Detecting Stealthy ConfuserEx with Yara

How to analyze ConfuserEx and write a Yara rule to detect obfuscated binaries that don't have the prominent watermark. #100DaysOfYARA

Participating in #100DaysOfYara, a challenge to write detection rules in the YARA format, I set myself a goal to write detections around the .NET architecture and prominent obfuscators. In this post, we will analyze the infamous ConfuserEx, an open-source obfuscator for .NET apps. Because it is readily accessible, it is likely one of the most frequently observed .NET obfuscators in malware. However, current rule coverage is lacking as most detections focus on the default watermark or other static names.
Existing coverage
Many existing Yara rules for ConfuserEx primarily target the default watermark commonly injected into obfuscated binaries. The watermark is injected during obfuscation and stored in a class extending Attribute. In .NET binaries, type names are encoded in UTF8 so that we can search for the name using a simple ASCII string in Yara.
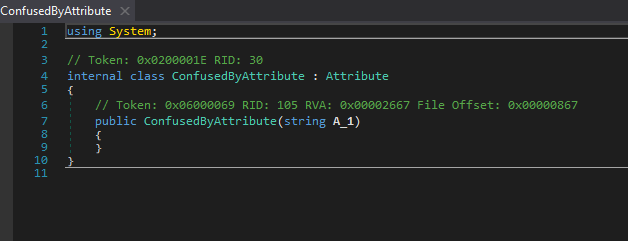
While this approach works in most cases, there are some limitations. Some forks of ConfuserEx allow users to disable/remove the watermark or change it to a custom name. It is also possible to patch the watermark using dnSpy or any .NET parsing library like AsmResolver. Without the watermark, most rules will fail to identify the binary as ConfuserEx obfuscated.
A Different Approach
When I looked the ConfuserEx source code for research I found something interesting, the typical long “random” escaped Unicode strings commonly found in obfuscated binaries are not as random as you might think.

We can also observe this when opening an obfuscated binary in dnSpy. Examining the names closer, we can observe the following:
- Equal in length
- Start with repeating characters
- End with the same character
From this, we can infer a pattern behind these names. Checking the source code reveals that there is indeed a pattern. Every generated name is appended with \u202e, making this a known value for our detection later. The hash that is supplied to the method is a XOR encrypted SHA1 hash. Given that it is a SHA1 hash, the resulting string will contain 40 characters. Our generated names will be 41 characters, accounting for the additional appended character.
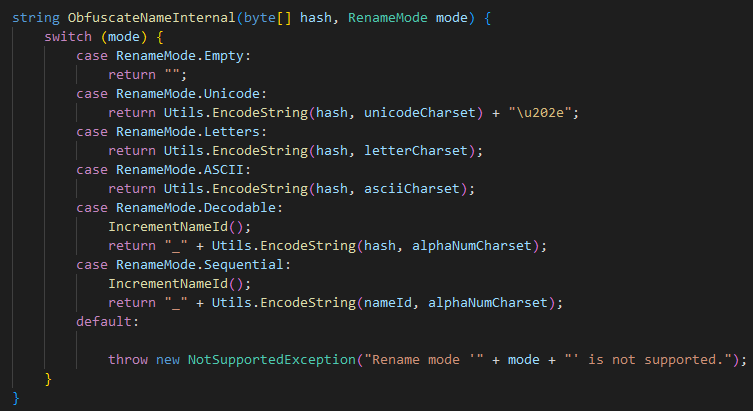 view the code here
view the code here
Now, if we look at the unicodeCharset used to encode the string, we can spot some more familiar values \u200B, the starting point of the Unicode ranges used to encode the strings.
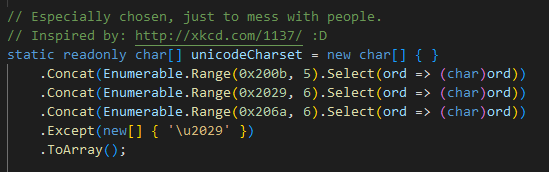
These starting points are also often part of the encoded strings as can be seen in the screenshot from dnSpy. To create our pattern, we must remember that type names are encoded in UTF-8, contrary to normal strings in .NET, which are encoded in UTF-16. To get the actual bytes of the obfuscated names, I used Malcat.
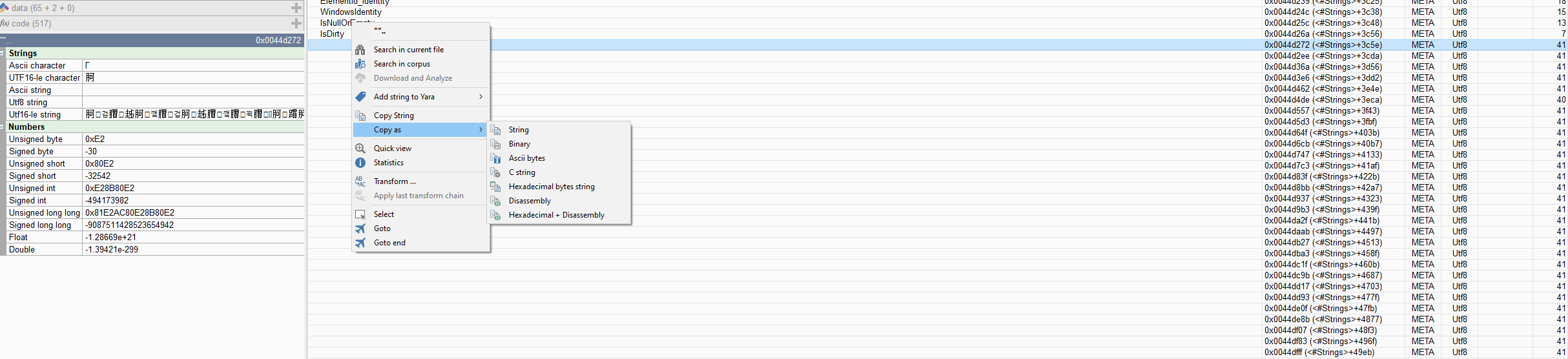
As previously described, the strings are exactly 41 characters in length. We can verify that we found the correct strings by checking the info tab on the left, showing us the UTF-16 encoded string consisting of random Chinese characters and zero-width spaces. Next, I used the Copy As feature to get a hexadecimal bytes string. Which looks something like this:
E2808BE280ACE281AEE2808DE2808BE280AEE281AEE281ACE2808BE2808DE281AEE280AEE281AAE281AFE281AFE280AAE2808CE2808EE280ADE281ADE2808EE280ACE281ABE2808DE2808EE281AFE280AAE280ABE2808DE280ADE281ABE281AEE2808CE280ABE281ABE281AEE281ACE2808DE2808BE2808CE280AEFor further examination, I compared multiple different strings and found a static pattern. All of these names start with E2, then two random bytes again, followed by E2. This continues until the end, where we see 80 AE, which is \u202e in UTF-8 encoded byte form. Since we have already deduced that the strings often start with the start ranges from the unicodeCharset I came up with the following:
$name_pattern = { E2 ( 80 8? | 81 AA ) E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 80 AE}The pattern assumes the starting characters \u202B-\u2013 or \u206A followed by random bytes alternating with E2 for 39 characters followed by the last static \u202E character. To make this pattern a rule, I added some extra conditions to verify we are dealing with a .NET binary. Since this pattern should be present multiple times in an obfuscated binary, I check if the pattern was found more than 5 times to ensure it’s actually a reused naming pattern.
The Finished Yara Rule
rule SUSP_OBF_NET_ConfuserEx_Name_Pattern_Jan24 {
meta:
description = "Detects Naming Pattern used by ConfuserEx. ConfuserEx is a widely used open source obfuscator often found in malware"
author = "Jonathan Peters"
date = "2024-01-03"
reference = "https://github.com/yck1509/ConfuserEx/tree/master"
hash = "2f67f590cabb9c79257d27b578d8bf9d1a278afa96b205ad2b4704e7b9a87ca7"
score = 60
strings:
$s1 = "mscoree.dll" ascii
$s2 = "mscorlib" ascii
$s3 = "System.Private.Corlib" ascii
$s4 = "#Strings" ascii
$s5 = { 5F 43 6F 72 [3] 4D 61 69 6E }
$name_pattern = { E2 ( 80 8? | 81 AA ) E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 [2] E2 80 AE}
condition:
uint16(0) == 0x5a4d
and 2 of ($s*)
and #name_pattern > 5
}